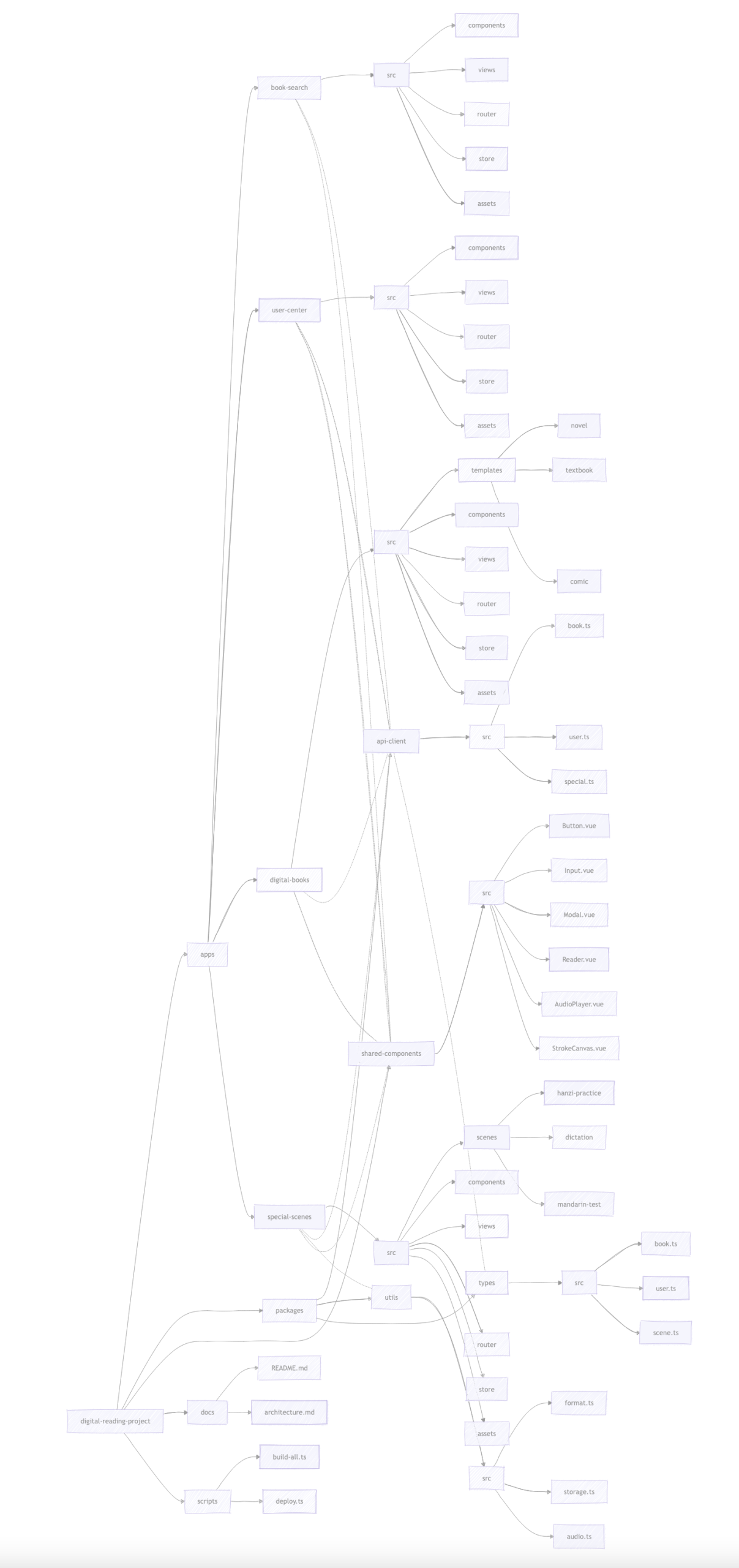
一、现有表结构梳理(适配映射)
现有的表 对应功能 映射到方案中 books 图书 books wordsets 词集(术语集) term_sets wordentries 词条(含子集) terms(树形) sections 段落 paragraphs completions 对话(也是一种“段落”) paragraphs(统一处理)
关键点:sections 和 completions 都作为 分析单元(paragraph),统一建模。
二、最终数据库设计(Laravel + MySQL 8 + SQLite 分片)
mermaid
graph LR
A[MySQL 8] --> B[books, wordsets, wordentries]
A --> C[sections, completions]
A --> D[book_wordset_summary 汇总表]
E[SQLite 分片] --> F[明细: section_wordentry / completion_wordentry]三、MySQL 8 表结构(Laravel Migration)1. books(已有)
php
Schema::create('books', function (Blueprint $table) {
$table->id();
$table->string('title');
$table->unsignedBigInteger('wordset_id')->nullable(); // 一本书一个词集
$table->timestamps();
});2. wordsets(词集)
php
Schema::create('wordsets', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->text('description')->nullable();
$table->timestamps();
});3. wordentries(树形词条,支持子集)
php
Schema::create('wordentries', function (Blueprint $table) {
$table->id();
$table->foreignId('wordset_id')->constrained()->cascadeOnDelete();
$table->unsignedBigInteger('parent_id')->nullable(); // 子集
$table->string('name');
$table->json('aliases')->nullable(); // 别名数组
$table->enum('type', ['subset', 'term']); // subset=子集, term=词条
$table->text('description')->nullable();
$table->timestamps();
$table->foreign('parent_id')->references('id')->on('wordentries')->nullOnDelete();
$table->index(['wordset_id', 'parent_id']);
});4. sections(段落)
php
Schema::create('sections', function (Blueprint $table) {
$table->id();
$table->foreignId('book_id')->constrained()->cascadeOnDelete();
$table->integer('section_index'); // 顺序
$table->text('content');
$table->integer('word_count')->default(0);
$table->timestamps();
$table->unique(['book_id', 'section_index']);
});5. completions(对话)
php
Schema::create('completions', function (Blueprint $table) {
$table->id();
$table->foreignId('book_id')->constrained()->cascadeOnDelete();
$table->integer('completion_index'); // 顺序
$table->text('content');
$table->integer('word_count')->default(0);
$table->timestamps();
$table->unique(['book_id', 'completion_index']);
});6. 核心:汇总表 book_wordset_summary
php
// database/migrations/2025_10_28_create_book_wordset_summary.php
Schema::create('book_wordset_summary', function (Blueprint $table) {
$table->unsignedBigInteger('book_id');
$table->unsignedBigInteger('wordentry_id');
$table->unsignedBigInteger('wordset_id');
$table->unsignedInteger('section_count')->default(0); // 在多少 section 出现
$table->unsignedInteger('completion_count')->default(0); // 在多少 completion 出现
$table->unsignedInteger('total_frequency')->default(0); // 总频次
$table->unsignedInteger('first_appear')->nullable(); // 首次出现位置(index)
$table->unsignedInteger('last_appear')->nullable(); // 末次出现
$table->primary(['book_id', 'wordentry_id']);
$table->index('wordset_id');
$table->index('wordentry_id');
$table->index(['wordset_id', 'section_count']);
$table->index(['wordset_id', 'completion_count']);
});四、SQLite 分片(明细存储)路径
bash
/storage/app/word_matrix/
├── 0000.db # book_id 0~9999
├── 0001.db # ... 每分片建表(两个表:section + completion)
sql
-- 每个 .db 文件包含
CREATE TABLE section_word (
section_id INTEGER NOT NULL,
wordentry_id INTEGER NOT NULL,
frequency INTEGER NOT NULL DEFAULT 1,
positions TEXT, -- JSON 数组
PRIMARY KEY (section_id, wordentry_id)
);
CREATE TABLE completion_word (
completion_id INTEGER NOT NULL,
wordentry_id INTEGER NOT NULL,
frequency INTEGER NOT NULL DEFAULT 1,
positions TEXT,
PRIMARY KEY (completion_id, wordentry_id)
);
CREATE INDEX idx_word_section ON section_word(wordentry_id);
CREATE INDEX idx_word_completion ON completion_word(wordentry_id);五、Laravel 分析任务(队列)
php
// app/Jobs/AnalyzeBookWordDistribution.php
class AnalyzeBookWordDistribution implements ShouldQueue
{
public function __construct(public Book $book) {}
public function handle()
{
$wordset = $this->book->wordset;
$leafTerms = $wordset->wordentries()->where('type', 'term')->get();
// 1. 构建 Aho-Corasick
$ac = new AhoCorasick();
foreach ($leafTerms as $term) {
$ac->add($term->name, $term->id);
foreach ($term->aliases ?? [] as $alias) {
$ac->add($alias, $term->id);
}
}
$ac->build();
// 2. 打开 SQLite 分片
$shard = sprintf("%04d", $this->book->id / 10000);
$dbPath = storage_path("app/word_matrix/{$shard}.db");
$sqlite = new \PDO("sqlite:$dbPath");
$sqlite->exec("PRAGMA journal_mode = WAL; PRAGMA synchronous = NORMAL;");
$stmtSection = $sqlite->prepare("
INSERT OR REPLACE INTO section_word
VALUES (?, ?, ?, ?)
");
$stmtCompletion = $sqlite->prepare("
INSERT OR REPLACE INTO completion_word
VALUES (?, ?, ?, ?)
");
// 3. 统计汇总
$stats = []; // wordentry_id => [sec_count, comp_count, freq, first, last]
// 处理 sections
foreach ($this->book->sections()->orderBy('section_index')->get() as $sec) {
$matches = $ac->search($sec->content);
foreach ($matches as $wid => $pos) {
$freq = count($pos);
$stmtSection->execute([$sec->id, $wid, $freq, json_encode($pos)]);
$stats[$wid]['sec'] = ($stats[$wid]['sec'] ?? 0) + 1;
$stats[$wid]['freq'] = ($stats[$wid]['freq'] ?? 0) + $freq;
$stats[$wid]['first'] ??= $sec->section_index;
$stats[$wid]['last'] = $sec->section_index;
}
}
// 处理 completions
foreach ($this->book->completions()->orderBy('completion_index')->get() as $comp) {
$matches = $ac->search($comp->content);
foreach ($matches as $wid => $pos) {
$freq = count($pos);
$stmtCompletion->execute([$comp->id, $wid, $freq, json_encode($pos)]);
$stats[$wid]['comp'] = ($stats[$wid]['comp'] ?? 0) + 1;
$stats[$wid]['freq'] = ($stats[$wid]['freq'] ?? 0) + $freq;
$stats[$wid]['first'] ??= $comp->completion_index + 10000; // 避免冲突
$stats[$wid]['last'] = $comp->completion_index + 10000;
}
}
// 4. 更新 MySQL 汇总表
foreach ($stats as $wid => $s) {
DB::statement("
INSERT INTO book_wordset_summary
(book_id, wordentry_id, wordset_id, section_count, completion_count, total_frequency, first_appear, last_appear)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
ON DUPLICATE KEY UPDATE
section_count = VALUES(section_count),
completion_count = VALUES(completion_count),
total_frequency = VALUES(total_frequency),
first_appear = LEAST(COALESCE(first_appear, 999999), VALUES(first_appear)),
last_appear = GREATEST(COALESCE(last_appear, 0), VALUES(last_appear))
", [
$this->book->id,
$wid,
$wordset->id,
$s['sec'] ?? 0,
$s['comp'] ?? 0,
$s['freq'],
$s['first'],
$s['last']
]);
}
}
}六、查询 API 示例1. 词集在多本书的覆盖率
php
public function coverage($wordsetId)
{
return DB::table('book_wordset_summary')
->join('wordentries', 'wordentry_id', '=', 'wordentries.id')
->where('wordset_id', $wordsetId)
->whereRaw('(section_count + completion_count) > 0')
->selectRaw('
wordentries.name,
COUNT(DISTINCT book_id) as book_count,
AVG(section_count) as avg_sections,
AVG(completion_count) as avg_completions
')
->groupBy('wordentry_id', 'wordentries.name')
->orderByDesc('book_count')
->get();
}七、自动分片初始化命令
php
// app/Console/Commands/InitWordMatrixShard.php
Artisan::command('wordmatrix:init {shard}', function ($shard) {
$path = storage_path("app/word_matrix/{$shard}.db");
if (file_exists($path)) return;
$sqlite = new PDO("sqlite:$path");
$sqlite->exec("
CREATE TABLE section_word (...);
CREATE TABLE completion_word (...);
CREATE INDEX ...
");
$this->info("Shard $shard created.");
});八、性能与存储
项目 估算 book_wordset_summary 50亿行 → ~300GB SQLite 分片 1000个 × 6GB = 6TB 总 ~6.3TB 服务器 1台 MySQL + 1台 NFS/本地盘