基于 Vue3 的 monorepo 架构设计一个数字阅读前端项目,需要清晰的模块划分和合理的目录结构,以支持图书搜索、用户登录、用户中心、数字图书模板以及特色应用场景(如汉字笔画练习、中英文字词听写、普通话语音测评等)。以下是一个详细的项目结构设计,采用 monorepo 方式,使用 apps、packages 和 shared-components 文件夹来组织子模块,同时考虑 Vue3 的组件化开发和复用性。
项目设计目标
- 模块化:通过 monorepo 架构,将不同功能模块(如搜索、用户中心、特色场景)拆分为独立子模块,便于维护和扩展。
- 复用性:将通用组件、工具函数和类型定义放在 shared-components 和 packages 中,供多个 apps 复用。
- 可扩展性:支持多种数字图书模板和特色应用场景,确保新功能可以轻松接入。
- 开发效率:使用 pnpm(推荐用于 monorepo)管理依赖,结合 Vite 作为构建工具,提升开发体验。
技术栈
- 框架:Vue3(组合式 API)
- 构建工具:Vite
- 包管理:pnpm(支持 monorepo 的 workspace 功能)
- 状态管理:Pinia
- 路由:Vue Router
- UI 组件库:可选(如 Element Plus 或 Naive UI),或基于 shared-components 自定义
- 类型检查:TypeScript
- 代码规范:ESLint + Prettier
- 测试:Vitest + Vue Test Utils
- 部署:支持静态部署(如 Vercel)或 SSR(如 Nuxt 3,可选)
项目结构
以下是项目的目录结构,分为 apps(应用入口)、packages(工具库和业务逻辑)、shared-components(通用组件)三大模块,并包含配置文件和文档。
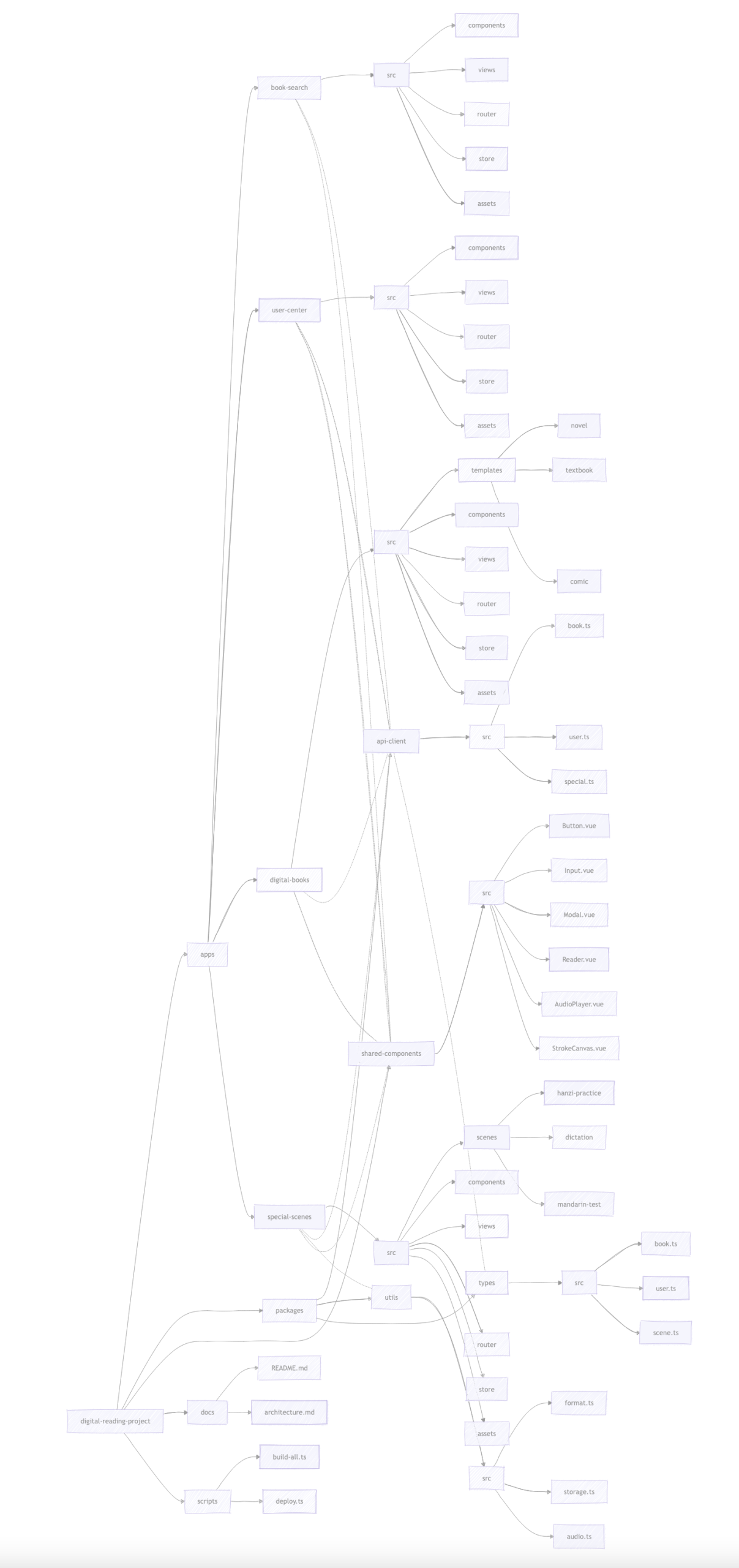
digital-reading-project/
├── apps/
│ ├── book-search/ # 图书搜索应用
│ │ ├── src/
│ │ │ ├── components/ # 搜索相关组件
│ │ │ ├── views/ # 页面视图
│ │ │ ├── router/ # 路由配置
│ │ │ ├── store/ # Pinia 状态管理
│ │ │ ├── assets/ # 静态资源
│ │ │ ├── App.vue # 应用根组件
│ │ │ └── main.ts # 入口文件
│ │ ├── vite.config.ts # Vite 配置文件
│ │ ├── package.json # 应用依赖
│ │ └── tsconfig.json # TypeScript 配置
│ ├── user-center/ # 用户中心应用(登录、个人资料等)
│ │ ├── src/
│ │ │ ├── components/ # 用户中心相关组件
│ │ │ ├── views/ # 页面视图(如个人资料、设置)
│ │ │ ├── router/
│ │ │ ├── store/
│ │ │ ├── assets/
│ │ │ ├── App.vue
│ │ │ └── main.ts
│ │ ├── vite.config.ts
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── digital-books/ # 数字图书模板应用
│ │ ├── src/
│ │ │ ├── templates/ # 多种图书模板
│ │ │ │ ├── novel/ # 小说阅读模板
│ │ │ │ ├── textbook/ # 教材阅读模板
│ │ │ │ └── comic/ # 漫画阅读模板
│ │ │ ├── components/
│ │ │ ├── views/
│ │ │ ├── router/
│ │ │ ├── store/
│ │ │ ├── assets/
│ │ │ ├── App.vue
│ │ │ └── main.ts
│ │ ├── vite.config.ts
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── special-scenes/ # 特色应用场景
│ │ ├── src/
│ │ │ ├── scenes/
│ │ │ │ ├── hanzi-practice/ # 汉字笔画练习
│ │ │ │ ├── dictation/ # 中英文字词听写
│ │ │ │ └── mandarin-test/ # 普通话语音测评
│ │ │ ├── components/
│ │ │ ├── views/
│ │ │ ├── router/
│ │ │ ├── store/
│ │ │ ├── assets/
│ │ │ ├── App.vue
│ │ │ └── main.ts
│ │ ├── vite.config.ts
│ │ ├── package.json
│ │ └── tsconfig.json
├── packages/
│ ├── api-client/ # API 请求封装
│ │ ├── src/
│ │ │ ├── index.ts # 导出 API 方法
│ │ │ ├── book.ts # 图书相关 API
│ │ │ ├── user.ts # 用户相关 API
│ │ │ └── special.ts # 特色场景 API
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── utils/ # 通用工具函数
│ │ ├── src/
│ │ │ ├── index.ts # 导出工具函数
│ │ │ ├── format.ts # 格式化工具(如时间、文本)
│ │ │ ├── storage.ts # 本地存储封装
│ │ │ └── audio.ts # 音频处理工具(如语音测评)
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── types/ # TypeScript 类型定义
│ │ ├── src/
│ │ │ ├── index.ts # 导出类型
│ │ │ ├── book.ts # 图书相关类型
│ │ │ ├── user.ts # 用户相关类型
│ │ │ └── scene.ts # 特色场景类型
│ │ ├── package.json
│ │ └── tsconfig.json
├── shared-components/ # 通用组件
│ ├── src/
│ │ ├── index.ts # 导出所有组件
│ │ ├── Button.vue # 通用按钮
│ │ ├── Input.vue # 通用输入框
│ │ ├── Modal.vue # 通用模态框
│ │ ├── Reader.vue # 通用阅读器组件
│ │ ├── AudioPlayer.vue # 音频播放器
│ │ └── StrokeCanvas.vue # 汉字笔画画布
│ ├── package.json
│ ├── vite.config.ts
│ └── tsconfig.json
├── scripts/ # 构建和部署脚本
│ ├── build-all.ts # 构建所有应用的脚本
│ └── deploy.ts # 部署脚本
├── docs/ # 项目文档
│ ├── README.md # 项目说明
│ └── architecture.md # 架构说明
├── .eslintrc.js # ESLint 配置
├── .prettierrc # Prettier 配置
├── pnpm-workspace.yaml # pnpm monorepo 配置文件
├── tsconfig.json # 全局 TypeScript 配置
├── vite.config.ts # 全局 Vite 配置(可选)
└── package.json # 根目录依赖目录结构说明
1. apps 目录
apps 包含独立的应用入口,每个应用是一个完整的 Vue3 项目,使用 Vite 构建,共享 packages 和 shared-components 的内容。
- book-search:
- 功能:图书搜索、分类浏览、搜索历史。
- 组件:搜索框、结果列表、筛选器。
- 路由:/search(搜索页)、/category(分类页)。
- 状态管理:Pinia 存储搜索关键词和结果。
- API 调用:通过 packages/api-client 获取图书数据。
- user-center:
- 功能:用户登录、注册、个人资料管理、阅读记录。
- 组件:登录表单、用户头像、设置面板。
- 路由:/login、/register、/profile。
- 状态管理:Pinia 存储用户信息和认证状态。
- API 调用:通过 packages/api-client 处理用户相关请求。
- digital-books:
- 功能:支持多种数字图书模板(如小说、教材、漫画)。
- 子目录 templates:
- novel:小说阅读模板,支持翻页、字体调整、夜间模式。
- textbook:教材模板,支持目录导航、笔记功能。
- comic:漫画模板,支持图片缩放、左右翻页。
- 组件:阅读器(基于 shared-components/Reader.vue)、目录、书签。
- 路由:/book/:id(阅读页面)、/book/:id/toc(目录页)。
- 状态管理:Pinia 存储阅读进度和设置。
- special-scenes:
- 功能:特色应用场景,如汉字笔画练习、中英文字词听写、普通话语音测评。
- 子目录 scenes:
- hanzi-practice:基于 Canvas 的汉字笔画练习,使用 shared-components/StrokeCanvas.vue。
- dictation:中英文字词听写,支持音频播放(基于 shared-components/AudioPlayer.vue)和输入验证。
- mandarin-test:普通话语音测评,使用 Web Speech API 或第三方语音服务,结合 packages/utils/audio.ts。
- 路由:/scene/hanzi、/scene/dictation、/scene/mandarin。
- 状态管理:Pinia 存储练习进度和评分。
2. packages 目录
packages 包含可复用的工具库和业务逻辑模块,供多个 apps 使用。
- api-client:
- 封装 Axios 或 Fetch 请求,提供图书、用户、特色场景的 API 方法。
- 示例:book.ts 包含 searchBooks、getBookDetail 方法;user.ts 包含 login、getProfile 方法。
- 使用 TypeScript 定义请求和响应类型,引用 packages/types。
- utils:
- 通用工具函数,如时间格式化、本地存储封装、音频处理。
- 示例:audio.ts 提供音频播放和录制功能,支持语音测评场景。
- types:
- 定义 TypeScript 类型和接口,如图书、用户、场景的数据结构。
- 示例:book.ts 定义 Book 接口,包含 id、title、author 等字段。
3. shared-components 目录
shared-components 包含通用 Vue 组件,支持跨应用复用。
- Button.vue:通用按钮,支持不同样式和禁用状态。
- Input.vue:通用输入框,支持搜索、表单等场景。
- Modal.vue:通用模态框,用于登录、提示等。
- Reader.vue:通用阅读器组件,支持小说、教材、漫画的渲染。
- AudioPlayer.vue:音频播放器,用于听写和语音测评。
- StrokeCanvas.vue:基于 Canvas 的汉字笔画练习组件。
4. 根目录配置
- pnpm-workspace.yaml:yaml
packages: - 'apps/*' - 'packages/*' - 'shared-components'定义 monorepo 的 workspace,允许 apps 和 packages 互相引用。 - tsconfig.json: 配置路径别名(如 @shared 指向 shared-components)和 TypeScript 选项。
- vite.config.ts: 全局 Vite 配置,定义共享的插件和优化选项,子应用可继承或覆盖。
- scripts:
- build-all.ts:使用 pnpm -r build 构建所有应用。
- deploy.ts:自动化部署脚本(可选)。
- docs:
- README.md:项目概述、安装和运行说明。
- architecture.md:详细描述 monorepo 架构和模块职责。
实现细节
1. Monorepo 管理
- 使用 pnpm 管理依赖,确保 apps 和 packages 的依赖隔离。
- 在 package.json 中配置脚本:json
{ "scripts": { "dev:search": "pnpm --filter book-search dev", "dev:user": "pnpm --filter user-center dev", "build": "pnpm -r build", "test": "pnpm -r test" } }
2. 组件复用
- shared-components 中的组件通过 index.ts 导出,供 apps 按需引入:ts
// shared-components/src/index.ts export { default as Button } from './Button.vue'; export { default as Reader } from './Reader.vue'; - 在 apps 中通过路径别名引入:ts
import { Button } from '@shared';
3. API 封装
- packages/api-client 使用 Axios 封装请求:ts
// packages/api-client/src/book.ts import axios from 'axios'; import type { Book } from '@types'; export async function searchBooks(query: string): Promise<Book[]> { const response = await axios.get('/api/books', { params: { query } }); return response.data; }
4. 特色场景实现
- 汉字笔画练习:
- 使用 StrokeCanvas.vue 实现 Canvas 画板,记录用户笔画并与标准笔顺比较。
- 数据通过 packages/api-client/special.ts 获取汉字笔顺信息。
- 中英文字词听写:
- 使用 AudioPlayer.vue 播放单词音频,用户输入答案后通过 packages/api-client 校验。
- 普通话语音测评:
- 使用 Web Speech API 录制用户语音,结合 packages/utils/audio.ts 进行预处理。
- 调用第三方语音测评 API(如科大讯飞)进行评分。
5. 路由和状态管理
- 每个 app 使用 Vue Router 管理页面跳转,Pinia 管理状态。
- 示例(book-search 的路由):ts
// apps/book-search/src/router/index.ts import { createRouter, createWebHistory } from 'vue-router'; import SearchView from '../views/SearchView.vue'; const router = createRouter({ history: createWebHistory(), routes: [ { path: '/search', component: SearchView }, { path: '/category', component: () => import('../views/CategoryView.vue') }, ], }); export default router;
6. 测试
- 使用 Vitest 和 Vue Test Utils 编写单元测试,覆盖组件和工具函数。
- 示例测试(shared-components/Button.vue):ts
import { mount } from '@vue/test-utils'; import Button from '@shared/Button.vue'; describe('Button', () => { it('renders correctly', () => { const wrapper = mount(Button, { props: { label: 'Click Me' } }); expect(wrapper.text()).toContain('Click Me'); }); });
开发流程
- 初始化项目:
- 初始化 monorepo:pnpm init 和 pnpm-workspace.yaml。
- 为每个 app 和 package 创建 package.json 和 vite.config.ts。
- 开发通用组件:
- 在 shared-components 中开发通用组件,先实现基础功能(如 Button、Input)。
- 逐步添加复杂组件(如 Reader、StrokeCanvas)。
- 开发工具库:
- 在 packages 中实现 API 客户端、工具函数和类型定义。
- 使用 TypeScript 确保类型安全。
- 开发应用:
- 从 book-search 开始,逐步实现其他 apps。
- 复用 shared-components 和 packages 的内容。
- 测试和部署:
- 编写单元测试,确保组件和工具函数的稳定性。
- 使用 scripts/build-all.ts 构建所有应用,部署到 Vercel 或其他平台。
可扩展性考虑
- 新增图书模板:在 apps/digital-books/templates 中添加新模板目录(如 magazine),复用 Reader.vue。
- 新增特色场景:在 apps/special-scenes/scenes 中添加新场景目录,复用现有组件和工具。
- 多语言支持:在 packages/utils 中添加 i18n 工具,使用 Vue I18n 实现多语言切换。
- 性能优化:使用 Vite 的按需加载和 Tree Shaking,减少打包体积。
总结
这个 monorepo 架构将数字阅读项目的功能模块化,清晰划分了 apps(应用入口)、packages(工具库)和 shared-components(通用组件)。通过 pnpm 和 Vite 管理依赖和构建,结合 Vue3 和 TypeScript 实现高效开发。每个子模块(图书搜索、用户中心、数字图书、特色场景)独立维护,同时复用通用代码,确保项目可扩展和易维护。